
GPU 메모리 사용량 초기화에 대한 포스팅입니다.
안녕하세요, Gil-It입니다. 오늘은 GPU 메모리 사용량 초기화에 대한 방법에 대하여 알아보도록 하겠습니다.
자연어 처리, Tensorflow(텐서플로우) 등을 주로 진행하는 업무상 GPU 메모리를 많이 사용하고있습니다. RTX 4090 3D Mark에 관한 포스팅을 읽어 보시면 왜 그래픽 카드 메모리 용량이 중요한지 설명해두었습니다.
저는 주로 텐서플로우로 작업을 많이 하고 있으며 텐서플로우는 모델 학습이 끝난 후에 자동으로 전용 메모리 사용량이 초기화가 될거라고 생각했는데 텐서플로우는 작업이 끝난 후에 자동으로 초기화가 안되는 부분을 확인하여 수동으로 초기화하는 방법을 공유하고자 합니다.
먼저, 작업을 하기전에 GPU 상태는 전용 메모리가 사용되고 있지 않음을 확인할 수 있습니다.
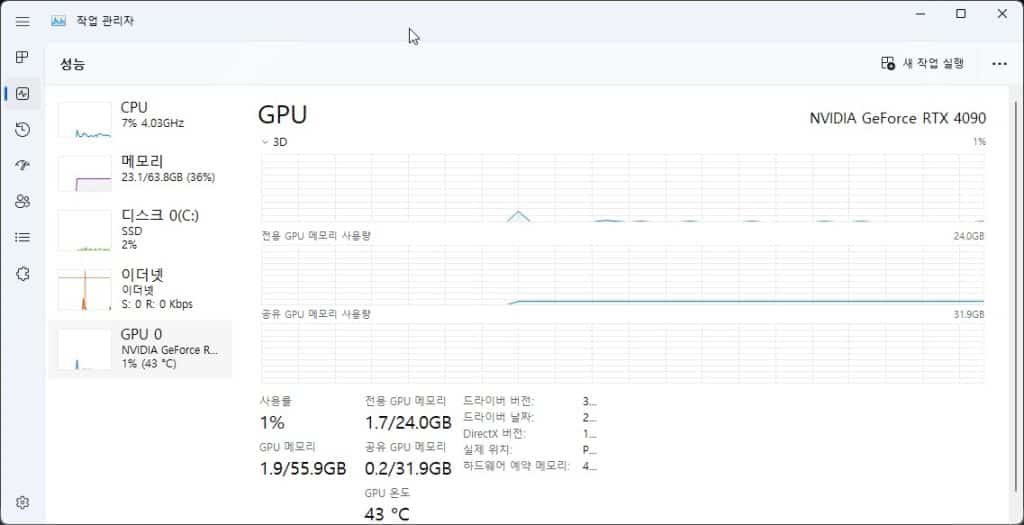
작업 전이기에 GPU가 사용되지 않고 있으며 전용 GPU 메모리가 대략 22GB, 온도 또한 43도로 보입니다.
지금부터는 텐서플로우의 활용 예제와 함께 살펴보도록 하겠습니다. 딥러닝, 머신러닝, AI에서 가장 자주 쓰이는 예시 중 하나인 이미지 분류 예시 데이터를 활용 하였으며 메모리 초기화가 목적이기에 전처리 등에 관한 내용은 생략 하였습니다. 전처리 등에 관한 자세한 내용은 링크를 통해서 확인하시면 됩니다.
#데이터 셋 불러오기
data_set = tf.keras.datasets.fashion_mnist
(train_input, train_target), (test_input, test_target) = data_set.load_data()
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz
29515/29515 [==============================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz
26421880/26421880 [==============================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz
5148/5148 [==============================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz
4422102/4422102 [==============================] - 0s 0us/step#target 값
target = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']#Model
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10)
])#Model Compile
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])#그래픽카드 메모리 확인
!nvidia-smi#모델 훈련 시작
model.fit(train_input, train_target, epochs=25)모델 훈련이 시작되면 GPU의 전용 GPU 메모리의 사용량이 다음 그림과 같이 증가합니다. 현재 에포크 4를 진행중에 있습니다.
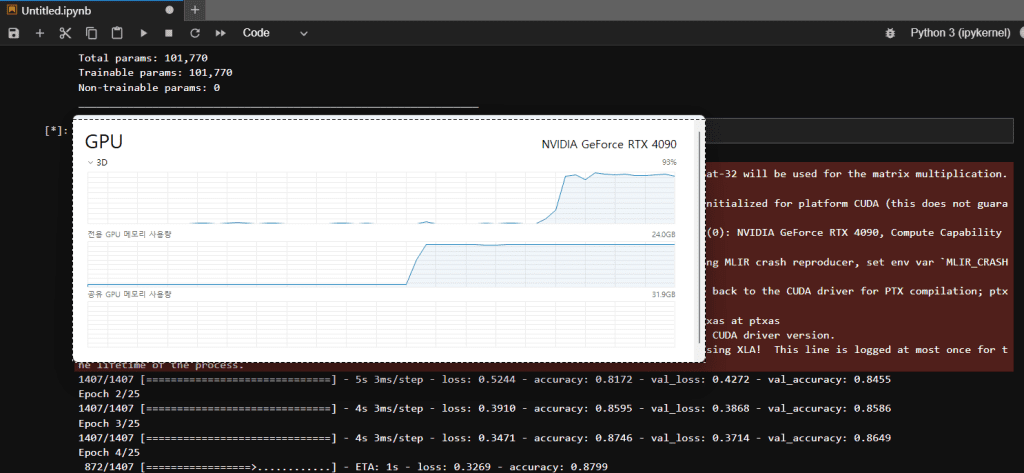
다음 그림과 같이 모든 학습이 종료되었음에도 불구하고 전용 그래픽 카드 메모리 사용량은 여전히 Max 값에 할당되어 있습니다. 이러한 경우에는 VRAM이 필요한 작업을 추가로 진행하게될 경우 Error 메세지가 발생하며 작업을 진행할 수 없습니다. 따라서, 메모리 초기화를 통하여 전용 메모리 사용량을 Clean하게 해준 뒤에 추가 작업을 해주셔야합니다.
GPU 전용 메모리의 초기화 작업은 매우 간단합니다!!
#numba 패키지를 설치합니다.
pip install numba#필요한 모듈을 import 합니다.
from numba import cuda
#이후 초기화 작업을 진행해줍니다.
device = cuda.get_current_device()
device.reset()numba 패키지를 통해서 cuda를 불러온 후, get_current_deivce() 함수를 통해서 현재 사용중인 device를 잡고 reset()을 진행합니다. 매우 간단하죠? 이렇게 진행을 하신다면 아래의 그림과 같이! 메모리 사용량이 다시 리셋이 되어서 줄어듭니다.
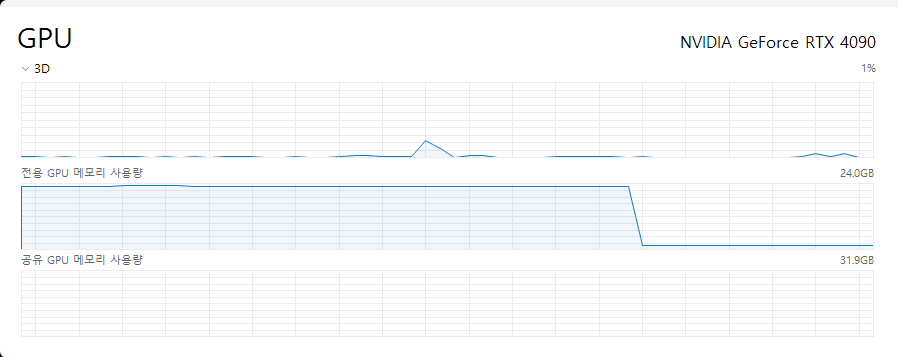
메모리가 초기화 되고난 후 다시 작업을 진행해주시면 됩니다. 물론 메모리 초기화 코드를 작업하시는 코드에 삽입하여서 진행하셔도 상관없습니다. 저는 주로 제가 작성한 코드의 제일 마지막 부분에 포함하여 모델 학습이 종료가 되면 자동으로 메모리가 초기화 되도록 보통 설정하여 합니다.
제가 아직 찾지 못한 부분일 수도 있습니다. 여기저기 다 서치해봐도 텐서플로우 자체에서 메모리 초기화를 하는 함수는 보지 못한 것 같습니다. 그 부분에 대해서 아시는 분 있으면 댓글 달아주세요!!